-
nGrinder를 활용한 어플리케이션 성능테스트Back-End/Spring 2023. 1. 6. 16:59728x90
nGrinder란?
네이버에서 The grinder라는 오픈소스를 참고하여 자바 언어를 기반으로 개발한 성능 측정 오픈소스이다.
nGrinder에서 사용되는 용어들
Controller
- 부하 테스트를 위한 GUI를 제공한다.
- 부하 테스트를 모니터링 할 수 있다.
Agent
- Controller가 전달한 script를 기반으로 target 서버에 부하를 발생시킨다.
- 각 Agent마다 사용 할 Process 및 Thread를 선택할 수 있다.
- 만약 2개의 프로세스와 4개의 스레드를 사용한다면, agent당 vUser의 수는 8이 된다.
- nGrinder 공식 위키에 따르면, single 4GB 미만의 메모리 및 2개의 CPU core를 사용한다면 프로세스의 개수를 10개 이하로 사용하기를 권장한다고 한다.(쓰레싱이 발생할 수 있기 때문) 마찬가지로, 쓰레드 갯수도 200개를 넘기지 않기를 권장한다.(heap 메모리 공유에 다른 OOM 문제 발생 위험)
Target Server
- 테스트를 진행 할 대상 서버이다.
nGrinder의 Architecture

먼저, Controller가 console과 현재 connection을 갖고 있는 agent를 활용하여 스크립트를 agent에게 분배한다.
해당 스크립트에는 vUser(서비스를 사용하고 있는 유저 수), processor, thread 등의 정보 및 수행해야 하는 코드가 groovy 언어 기반으로 작성된다.
테스트가 시작되면, agent들은 해당 script를 실행하여 target server로 request를 보내기 시작한다.
이와 동시에, controller는 target server를 모니터링하게 된다.
nGrinder 측정 수행
- Controller와 agent 모두 동일한 서버(로컬PC)에서 수행
- pc는 M1 Pro(10코어), 16GB 메모리
- 1개의 agent 사용
- api는 페이징 쿼리가 포함된 조회 api
1. Vusers가 10(2개의 process, 각 5 쓰레드) 일 때

2. Vusers가 50(2개의 process, 각 25 쓰레드) 일 때

3. Vusers가 198(6개의 process, 각 33 쓰레드) 일 때
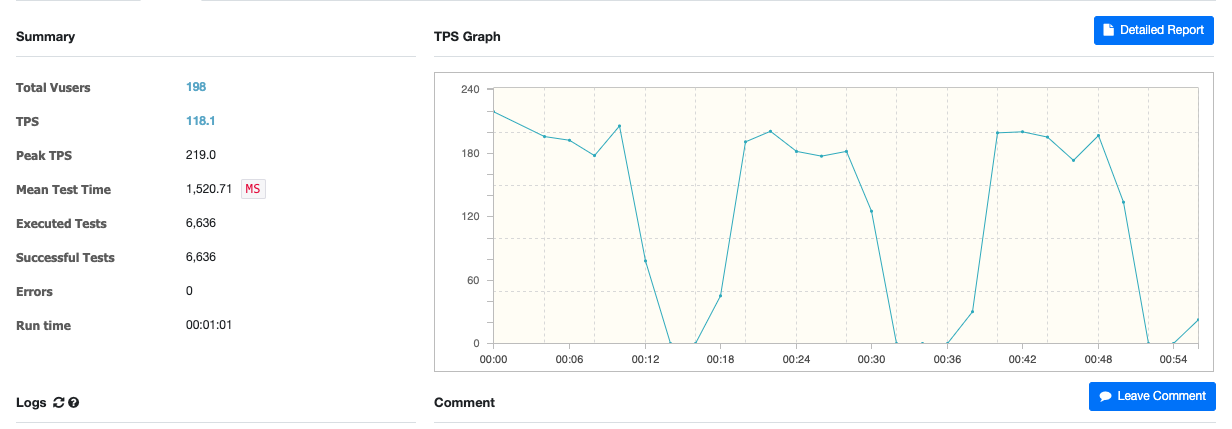
- 평균 응답시간(MTT)이 1.5초가 나왔다. 따라서, Vuser의 수치를 더 낮추어 보기로 했다.
4. Vusers가 99(3개의 process, 각 33 쓰레드) 일 때

- 평균 응답시간이 0.77초가 나왔다.
- 따라서, 대략적으로 130명의 동시접속자가 있을 때, 1초 미만의 응답 처리가 가능할 것이라고 추측이 된다.
어떻게 하면 성능을 향상시킬 수 있을까
- 해당 질문에 대한 답변은 너무나도 그 범위가 크고, 방법이 많기 때문에 몇 가지를 언급하면
- 역시 가장 단순한 방법은, 서버의 scale up이라고 할 수 있다.
- 사실 비교자체가 그렇긴 하지만.. 예시로 target 서버를 내 로컬 pc로 하고 성능을 측정했을 때 Vuser가 400일 때도 TPS가 900을 기록하였다.
- scale out도 생각 해 볼 수 있다.
- 현재 사내 클라우드 서비스를 통해 dev존에서 테스트를 진행하고 있는데, 파드를 1개만 띄워서 사용을 하고 있다. 만약 레플리카셋을 통해 3개의 파드를 띄운다면 더 성능이 나아질 것이다.
- 물론 이 경우 nginx를 활용한 로드밸런싱을 어떻게 설계할 지도 고려를 해야 한다.
- 현재 사내 클라우드 서비스를 통해 dev존에서 테스트를 진행하고 있는데, 파드를 1개만 띄워서 사용을 하고 있다. 만약 레플리카셋을 통해 3개의 파드를 띄운다면 더 성능이 나아질 것이다.
- 코드 리팩토링도 중요하다.
- 기본적으로, 웹 서비스는 CUD보다 R과 관련된 요청이 압도적으로 많다고 한다. 따라서 테이블에 적절하게 인덱싱을 하거나, 코드 내적으로 fetch join과 같은 방법을 통해 성능을 최적화하는 것도 성능 향상에 도움이 된다고 생각된다.
- 쿼리 튜닝을 잘 하자
- 예를 들어 db 접근 기술로 mybatis를 사용한다면, bulk insert(update)작업 진행 시 batch 모드를 활용해도 좋고, 적절하게 index를 걸거나 실행계획을 분석하여 인덱스가 잘 동작하는지, 안티패턴은 없는지 등을 체크하는 것 등이 중요하다고 생각한다.
- 역시 가장 단순한 방법은, 서버의 scale up이라고 할 수 있다.
Ref.
https://github.com/naver/ngrinder/wiki/User-Guide
GitHub - naver/ngrinder: enterprise level performance testing solution
enterprise level performance testing solution. Contribute to naver/ngrinder development by creating an account on GitHub.
github.com
nGrinder 설치 (부하 테스트)
nGrinder란? nGrinder는 네이버에서 성능 측정 목적으로 jython(JVM위에서 파이썬이 동작)으로 개발 된 오픈소스 프로젝트이며, 2011년에 공개 하였습니다. 바닥부터 개발을 한 것이 아니라 The Grinder라는
jy-p.tistory.com
'Back-End > Spring' 카테고리의 다른 글
멀티 모듈 구현 시 발생했던 git 관련 이슈 (0) 2023.08.06 Stream을 List로 변환하는 2가지의 방법(Collectors.toList(), Stream.toList()) (1) 2023.04.18 Spring Rest docs를 활용한 API 명세를 openapi3를 활용하여 swagger로 변환하기 (0) 2022.12.13 Spring Security cors 이슈 (0) 2022.10.21 MapStruct 라이브러리 사용법 (0) 2022.08.29