-
kafka란?Back-End/Kafka 2021. 10. 21. 20:54728x90
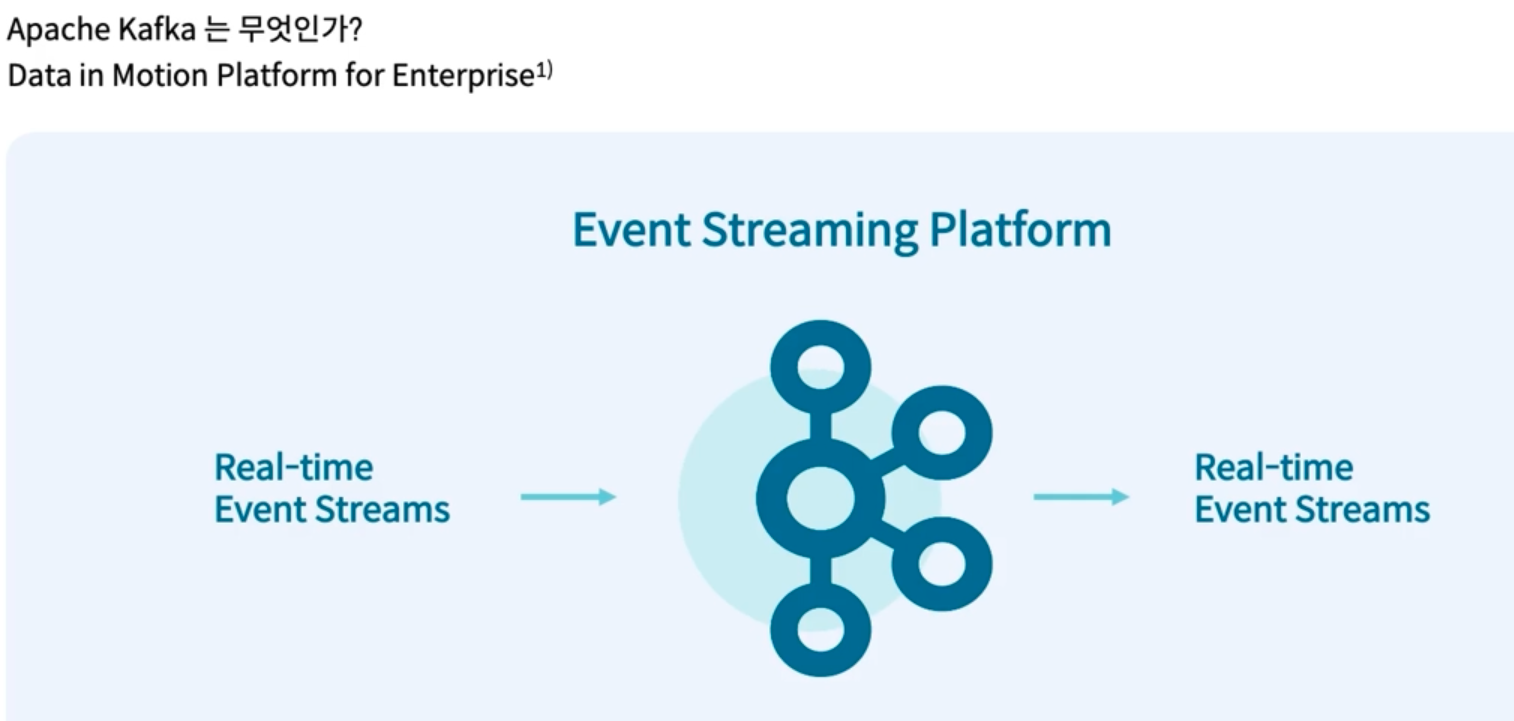



공식 문서를 보면, kafka는 다음과 같이 정의되어 있다.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
kafka와 RabbitMQ의 성능 비교
https://www.confluent.io/blog/kafka-fastest-messaging-system/
- source application은 kafka에 data를 전송하고, target application은 kafka에서 data를 가져온다.
ex) source에서 쇼핑몰의 클릭로그, 결제로그 등을 kafka에 보내고, target에서는 로그를 적재하고, 처리한다.
TOPIC
- kafka에는 다양한 데이터가 들어갈 수 있는데, 그러한 데이터가 들어갈 수 있는 공간을 topic이라고 한다.
- 파일이나 디렉토리 형태로 보이진 않는다.
- topic을 일반적인 AMPQ와는 다르게 동작한다. topic은 데이터베이스의 테이블과 유사한 성질을 가진다. producer가 메세지를 produce 해서 topic에 data를 담으면, consumer가 topic에서 메세지를 가져가는 방식이다.
- 하나의 consumer는 하나의 consumer Group에 포함되고, Consumer Group 내의 Consumer들은 협력하여 Topic의 메세지를 분산 병렬 처리한다.
- Producer와 Consumer는 서로 알지 못하고, 각각의 고유의 속도로 Commit Log에 Write, read를 수행한다. 다른 Consumer Group에 속한 Consumer들은 서로 관련이 없고,
- Commit Log는 추가만 가능하고 변경이 불가능한 데이터 스트럭쳐이다. 데이터(Event)는 항상 로그 끝에 추가되고 변경되지는 않는다.
- topic은 click_log, send_sms와 같이 그 이름을 명확히 하는것이 유지/보수에 좋다.
- topic 내부에는 여러 개의 partition이 존재하는데, partition에 queue 형식으로 data가 쌓이면, consumer는 오래된 데이터부터 순서대로 이를 가져간다. 여기서, consumer가 데이터를 가져가도 partition 내부의 data는 사라지지 않는다.

- 서로 다른 그룹의 consumer group은 data를 처음부터 여러 번 참조할 수 있는데, 이는 kafka를 사용하는 이유 중 하나이다. 예를 들어 첫 번째 consumer가 ElasticSearch, 두 번째 consumer가 Hadoop이라면 이들은 각각 click_log topic에서 데이터를 수집 할 수 있다.
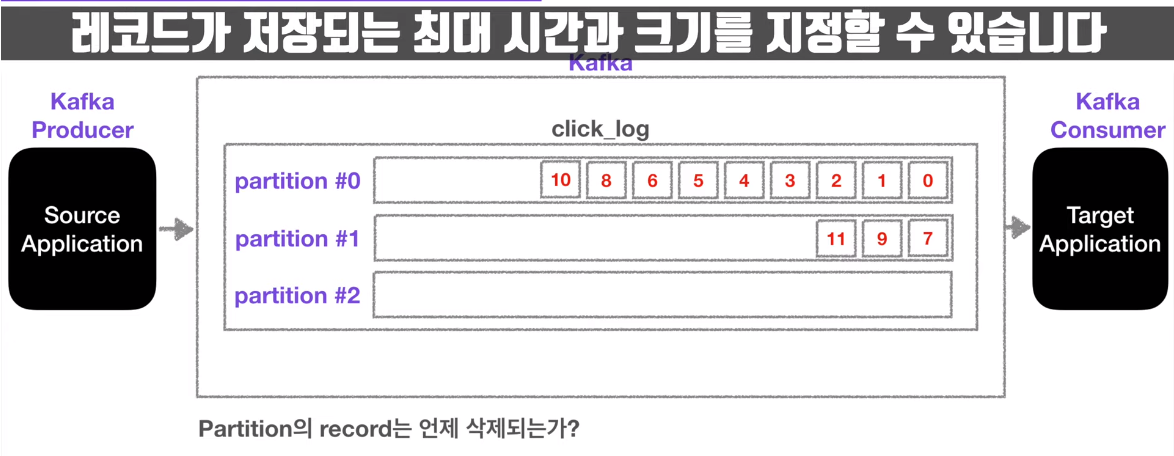
- partition은 여러 개를 생성할 수 있다. 이러한 경우, data는 특별한 option을 주지 않는다면 round-robin 방식으로 저장이 된다.
- partition이 record를 얼마나, 어느 시간 만큼 저장할 지는 옵션으로 정할 수 있다.
kafka broker
- broker는 kafka가 설치되어 있는 서버 단위를 의미한다. 보통 3개 이상의 broker를 두는 것을 권장한다.
- 카프카 브로커는 일반적으로 '카프카'라고 불리는 시스템을 말합니다. 프로듀서와 컨슈머는 별도의 애플리케이션으로 구성되는 반면, 브로커는 카프카 자체이기 때문입니다. 따라서 '카프카를 구성한다' 혹은 '카프카를 통해 메시지를 전달한다'에서 카프카는 브로커를 의미합니다.
- 1개의 broker에 partition이 존재하고, replication을 3으로 지정하면 나머지 2개의 broker에 partition이 추가로 복제된다. 이 때, 원본 partition은 leader partition, 복제본 partition을 follower partition이라고 한다. 그리고 이들을 합치면 In sync replica이다.

- replication을 사용하는 이유는, 고가용성 때문이다. 만약 leader partition이 있는 broker가 고장이 나거나 하여 사용이 불가능할 때, follwer partition이 있는 broker를 사용해서 data를 활용할 수 있게 된다.

- producer가 kafka topic의 leader partition에 data를 전달할 때, 상세 옵션중 'ack'가 있는데 이는 0,1,all 3개의 값을 갖는다.
- '0' 옵션을 준 경우, producer가 data를 전달한 후, leader partition으로부터 잘 전달되었음을 의미하는 ack 응답을 받지 않는다.
- '1' 옵션을 준 경우, leader partition으로부터 잘 전달되었음을 의미하는 ack 응답을 받는다. 하지만, 해당 data가 follwer partition까지 잘 전달이 되었는지에 대한 ack 응답은 받지 않는다.
- 'all' 옵션을 준 경우, leader partition으로부터 잘 전달되었음을 의미하는 ack 응답을 받고, 해당 data가 follwer partition까지 잘 전달이 되었는지에 대한 ack 응답까지 받게 된다. 안정성이 높은 옵션이지만 그만큼 속도는 현저히 떨어지게 된다.
kafka broker
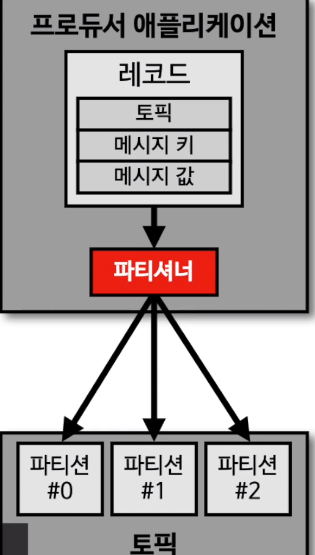

- producer가 data를 전송할 때, 토픽의 어느 파티션에 전송이 될 지는 파티셔너가 결정을 한다.
- message key를 가진 record는 파티셔너에 의해 hash값이 생성되고, 이 hash를 기준으로 어느 파티션에 들어갈 지가 결정되게 된다.
- 예를 들면, 서울의 온도값을 단일 파티션에 넣기 위해, message key로 '서울'을 주면 항상 동일한 hash값이 나오므로, 동일한 partition으로 record가 기록됨으로써 순서가 보장될 수 있다.
- message key가 없는 경우는 round-robin으로 들어가게 된다.
- kafka에서는 custom partitioner를 제공한다. 예를 들면, 특정 VIP고객에게 record를 더 몰아주는 식으로도 partition을 구성할 수 있다.
kafka lag
- kafka producer는 topic의 파티션에 데이터를 차곡차곡 넣는다. partition에 데이터가 들어가면, 각 데이터는 offset이 붙게 된다. 여기서, consumer의 offset과 producer의 offset에 차이가 발생할 수 있는데, 이를 kafka lag이라고 한다.

- 또한, partition이 여러 개인 경우, lag은 여러 개가 존재할 수 있다.
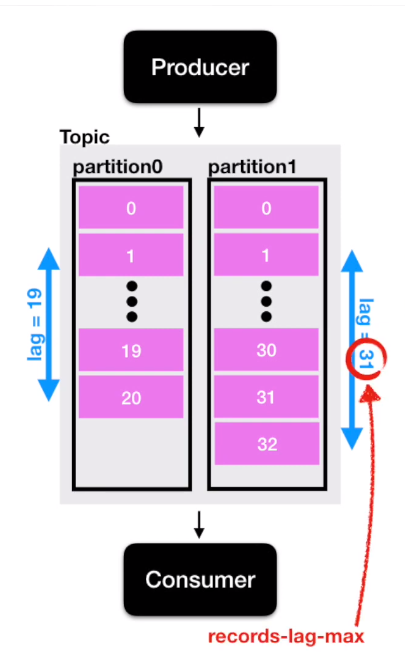
- kafka lag이 발생하는 경우, consume 속도를 빠르게 하기위해 partition을 늘리면서 consumer group 내의 consumer 인스턴스도 늘려주어야 한다.
- 컨슈머 그룹 내에서, 하나의 파티션은 단 하나의 컨슈머와 연결이 가능하다. 반대로 하나의 컨슈머는 여러 개의 파티션을 읽어올 수 있다. 하지만 1대1 매칭보다 컨슘 속도가 오래걸리므로 1대1이 가장 이상적이다.
'Back-End > Kafka' 카테고리의 다른 글
[Spring-kafka] MSA 환경에서 토픽 이름에 맞게 KafkaMessage 역직렬화하여 수신하기 (0) 2024.10.13 웹 크롤러에 Kafka 도입(2) (0) 2022.04.01 웹 크롤러에 Kafka 도입 (0) 2022.03.30